| [[WM:TECHBLOG]] |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| All Things Linguistic |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Andy Mabbett, aka pigsonthewing. |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Anna writes |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| BaChOuNdA |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Bawolff's rants |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Between the Brackets: a MediaWiki Podcast |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Blog on Taavi Väänänen |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Blogs on Santhosh Thottingal |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Bookcrafting Guru |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| brionv |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Catching Flies |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Clouds & Unicorns |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Cogito, Ergo Sumana tag: Wikimedia |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Cometstyles.com |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Commonists |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Content Translation Update |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| cookies & code |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Damian's Dev Blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Design at Wikipedia |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| dialogicality |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Diff |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Doing the needful |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Durova |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Ed's Blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Einstein University |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Endami |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| English Wikipedia administrators' newsletter |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Fae |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Federico Leva |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| FOSS – Small Town Tech |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Gap-finding Project |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Geni's Wikipedia Blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| http://ad.huikeshoven.org/feeds/posts/default/-/wiki |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| http://blog.maudite.cc/comments/feed |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| http://blog.pediapress.com/feeds/posts/default/-/wiki |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| http://blog.robinpepermans.be/feeds/posts/default/-/PlanetWM |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| http://bluerasberry.com/feed/ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| http://brianna.modernthings.org/atom/?section=article |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| http://feeds.feedburner.com/ThoughtsForDeletion^ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| http://magnusmanske.de/wordpress/?feed=rss2 |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| http://moriel.smarterthanthat.com/tag/mediawiki/feed/ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| http://terrychay.com/category/work/wikimedia/feed |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| http://wikipediaweekly.org/feed/podcast |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| http://www.greenman.co.za/blog/?tag=wikimedia&feed=rss2 |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| http://www.phoebeayers.info/phlog/?cat=10&feed=rss2 |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| https://blog.ash.bzh/en/feed/ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| https://blog.bluespice.com/tag/mediawiki/feed/ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| https://blog.kevinpayravi.com/tag/wikimedia/feed/ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| https://blog.wikimedia.de/tag/Wikidata+English/feed/ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| https://hexmode.com/category/wmf/feed/atom/ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| https://logic10.tumblr.com/ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| https://lu.is/wikimedia/feed/ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| https://mariapacana.tumblr.com/tagged/parsoid/rss |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| https://medium.com/feed/@nehajha |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| https://thewikipedian.net/feed/ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| https://tttwrites.wordpress.com/category/wikimedia/feed/ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| https://wandacode.com/category/outreachy-internship/feed/ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| https://wikistrategies.net/category/wiki/feed/atom/ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| https://wllm.com/tag/wikipedia/feed/ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| https://www.guillaumepaumier.com/category/wikimedia/feed/ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| https://www.residentmar.io/feed |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| https://www.wikiphotographer.net/category/wikimedia-commons/feed/ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| in English Archives - Wikimedia Suomi |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| International Wikitrekk |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Language and Translation |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Laura Hale, Wikinews reporter |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Leave it to the prose |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Make love, not traffic. |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Mark Rauterkus & Running Mates ponder current events |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| MediaWiki and Wikimedia – etc. etc. |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| MediaWiki Testing |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| MediaWiki – addshore |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| MediaWiki – Chris Koerner |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| mediawiki – Hexmode's Weblog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| MediaWiki – It rains like a saavi |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| MediaWiki – Ryan D Lane |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Ministry of Wiki Affairs |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Muddyb Mwanaharakati |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Musings of Majorly |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| My Outreachy 2017 @ Wikimedia Foundation |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| NonNotableNatterings |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Notes from the Bleeding Edge |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Nothing three |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Okinovo okýnko |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Open Codex |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Open Source Exile |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Original Research |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Pablo Garuda |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Pau Giner |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Personal – The Moon on a Stick |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Phabricating Phabricator |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Planet Wikimedia Archives - Entropy Wins |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Planet Wikimedia – OpenMeetings.org | Announcements |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| planetwikimedia – copyrighteous |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Political Bias on Wikipedia |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Posts (#wikimedia) |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Professional Wiki Blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| project-green-smw |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| ProWiki Blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Ramblings by Paolo on Web2.0, Wikipedia, Social Networking, Trust,
Reputation, … |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Rock drum |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Routing knowledge |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Sam Wilson's notebook |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Sam Wilson: Wikimedia |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Sammy's Blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Score all the things |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Scripts++ |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Semantic MediaWiki – news |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Sentiments of a Dissident |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Stories by Megha Sharma on Medium |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Sue Gardner's Blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Tech News weekly bulletin feed |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Technical & On-topic – Mike Baynton’s Mediawiki Dev Blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| The Academic Wikipedian |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| The Lego Mirror - MediaWiki |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| The life of James R. |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| The Signpost |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| The Speed of Thought |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| TheDJ writes |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| This Month in GLAM |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Timo Tijhof |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Ting's Wikimedia Blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Tyler Cipriani: blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Vinitha's blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| weekly – semanario – hebdo – 週刊 – týdeník – Wochennotiz – 주간 –
tygodnik |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| What is going on in Europe? |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wiki Education |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wiki Loves Monuments |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wiki Northeast |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wiki Playtime - Medium |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wiki – David Gerard |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wiki – Gabriel Pollard |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wiki – Our new mind |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wiki – stu.blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wiki – The life on Wikipedia – A Wikignome's perspecive |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wiki – Ziko's Blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wiki-en – [[content|comment]] |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikibooks News |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikimedia Australia news |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikimedia DC Blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikimedia Design Blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikimedia Europe |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikimedia Foundation |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikimedia on Kosta Harlan |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikimedia Security Team |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikimedia Status - Incident History |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikimedia Tech News |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikimedia | ഗ്രന്ഥപ്പുര |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wikimedia – andré klapper's blog. |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wikimedia – apergos' open musings |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wikimedia – Bitterscotch |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikimedia – DcK Area |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wikimedia – Harsh Kothari |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikimedia – Jan Ainali |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wikimedia – millosh’s blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wikimedia – Open World |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wikimedia – Thomas Dalton |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikimedia – Tim Starling's blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikimedia – Witty's Blog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikinews Reports |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikipedia & Linterweb |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikipedia - nointrigue.com |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikipedia Archives — Andy Mabbett, aka pigsonthewing. |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikipedia Notes from User:Wwwwolf |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikipedia – Aharoni in Unicode |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wikipedia – Andrew Gray |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikipedia – Blossoming Soul |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikipedia – Bold household |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wikipedia – Going GNU |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikipedia – mlog |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikipedia – ragesoss |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wikipedia – The Longest Now |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikipedian in Residence for Gender Equity at West Virginia
University |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| WikiProject Oregon |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikisorcery |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wikistaycation |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| wikitech – domas mituzas |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| WMUK |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Words and what not |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Wow. So wikimedia. Such quality. Many testing. Very team. |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Writing Within the Rules |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| XD @ WP |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| {{Hatnote}} |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
| Ø |
XML |
Monday, 30 December 2024 17:01 |
Monday, 30 December 2024 18:01 |
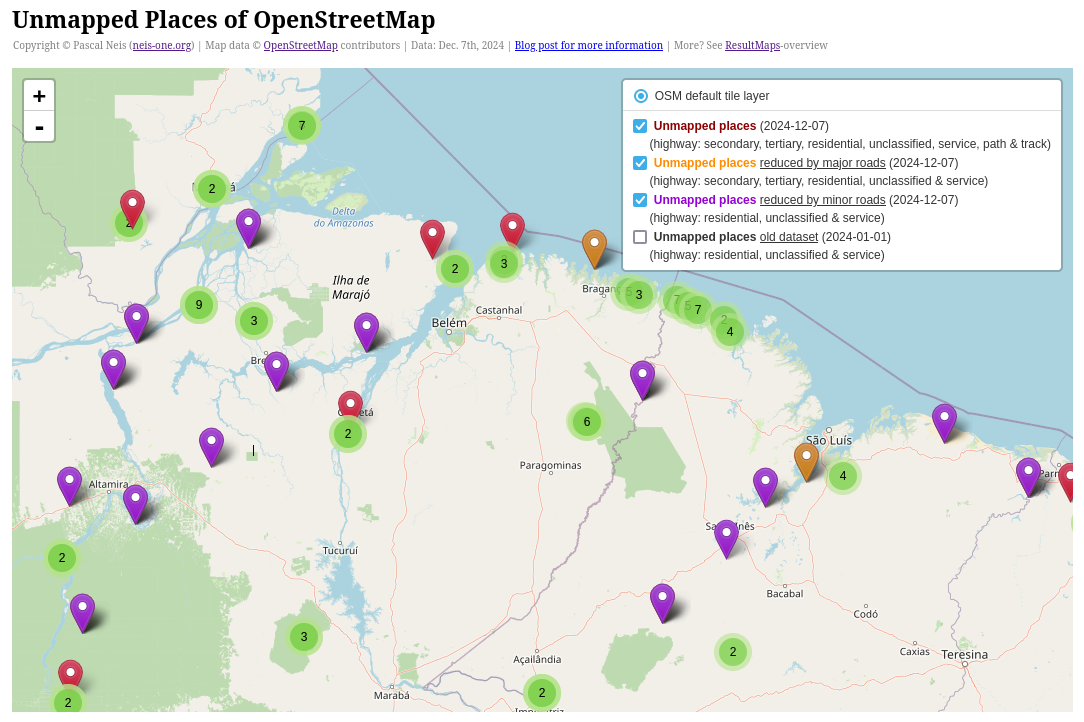
 /
/ their correspondence table
between the CNEFE 2022 variables (The Brazilian National Address
Register for Statistical Purposes) and the OSM labels for mapping
educational POIs. This phase is part of the effort to
their correspondence table
between the CNEFE 2022 variables (The Brazilian National Address
Register for Statistical Purposes) and the OSM labels for mapping
educational POIs. This phase is part of the effort to 
 /
/ ►
► ►
►


















.jpg)




.jpg)


.svg)
.jpg)





.JPG)






.jpg)
.jpg)




.jpg)































 the programme
the programme
 , on
the OSM France forum, that there is a humanitarian mapping project
in response to Cyclone Chido, which recently impacted Mayotte, a
French overseas territory off the southeastern coast of
Africa.
, on
the OSM France forum, that there is a humanitarian mapping project
in response to Cyclone Chido, which recently impacted Mayotte, a
French overseas territory off the southeastern coast of
Africa.

































{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
Discuss this story
Is it not a serious BLP issue to call Mangione a murderer without a conviction? Sincerely, Dilettante 14:07, 25 December 2024 (UTC)[reply]